Hi All,
I’m wondering how to use alignments in formulas in the data cube, calculated element transformation…

As illustration this is what I want to end up with:
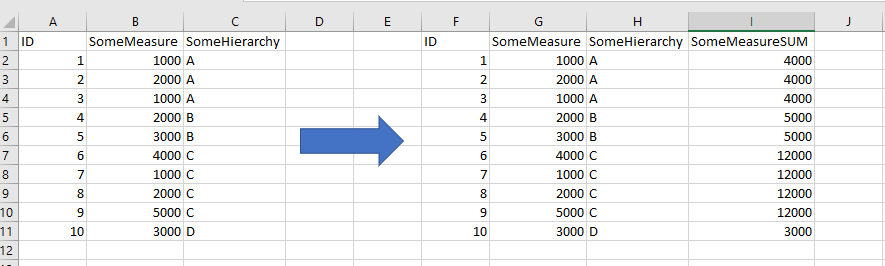
But when adding a calculated element like this: return SUM($SomeMeasure$,$SomeHierarchy$)
I instead end up with:
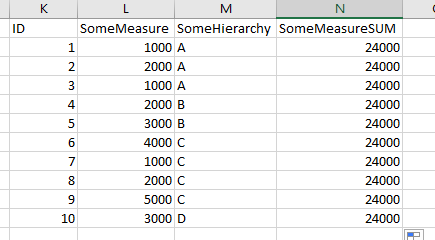
I need to keep the ID in the result (and I have a bunch of other fields in the data cube also, so I haven’t been able to get the result I need with the aggregate transform.)
This works excellent when calculated in the metric set, but I want to re-use this calculation across many metric sets, hence why I want the calculation in the data cube.
What I’m I missing here?

